
«Болото с ужасной быстротой засасывало нас глубже и глубже. Вот уже всё туловище моего коня скрылось в зловонной грязи, вот уже и моя голова стала погружаться в болото, и оттуда торчит лишь косичка моего парика.
Что было делать? Мы непременно погибли бы, если бы не удивительная сила моих рук. Я страшный силач. Схватив себя за эту косичку, я изо всех сил дёрнул вверх и без большого труда вытащил из болота и себя, и своего коня, которого крепко сжал обеими ногами, как щипцами.»
Рудольф Эрих Распэ «Приключения барона Мюнхгаузена»
В нынешней ситуации, чтобы не сойти с ума, совершенно необходимо иметь какие-то, казалось бы, примитивные, но всё же некоторые якоря, удерживающие тебя на плато нормального функционирования. Помимо музыкальных занятий, регулярной чистки зубов, уборки в квартире и прочего быта, это, в частности, работа и некоторые усилия по ведению сетевого дневника. На этот раз речь пойдёт про сервис реверс-прокси и балансировщика, который я внедрил на работе.
Изначально был очень старый веб-сервер, на котором крутились сайты (Ubuntu 8.04 x86, Apache 2.2, PHP 5.2). Веб-сервер этот стоял за WAF (web application firewall), который сам по себе был старым и, естественно, имел множество уязвимостей. WAF был выставлен в интернет за шлюзом, который просто пробрасывал порты, т. е., WAF был начальной точкой входа, что само по себе неправильно.
Так как при проведении более-менее многолюдных мероприятий в организации и соответственном росте количества запросов к сайтам начинались тормоза и зависания — а иногда это было и на ровном месте — хотелось выяснить, почему это происходит, при какой нагрузке, собрать какую-то статистику. В WAF в качестве проксирующего сервиса используется nginx, и я обратился в их техподдержку с просьбой поставить на nginx модуль ngx_http_stub_status_module, с помощью которого можно было бы собирать данные о количестве соединений и запросов и передавать их в Zabbix.
Через некоторое время я получил ответ, что версия nginx на нашем сервере очень старая и установить этот модуль не представляется возможным. Также мне сообщили, что nginx выполняет сугубо прикладную функцию и настраивать его более изощрённо для реализации какой-то защиты и тонких настроек реверс-проксирования не планируется даже при наличии более новой версии WAF. Тогда я решил оставить WAF в покое и сделать нормальный сервис реверс-прокси и балансировки на базе HAProxy.
Целью было сделать так, чтобы на WAF и внутренние сервера поступал уже более-менее отфильтрованный трафик, чтобы они не перегружались и выполняли свою работу, не отвлекаясь на обработку мусорных запросов, заодно терминировать HTTPS до WAF (т. е., держать сертификаты SSL на HAProxy), иметь возможность оперативно пускать трафик мимо WAF и вообще, как-то улучшить контроль над системой и её отказоустойчивость, настроить мониторинг и собирать статистику. Вторым этапом нужно было обновить сам WAF, но пока выключить его без простоя было невозможно и заместить его было пока нечем. Тем не менее, разработчики WAF обещали сделать кластер из двух узлов, когда настанет подходящее для этого время.
После довольно долгой работы по сбору информации, планирования и реализации получилось следующее:
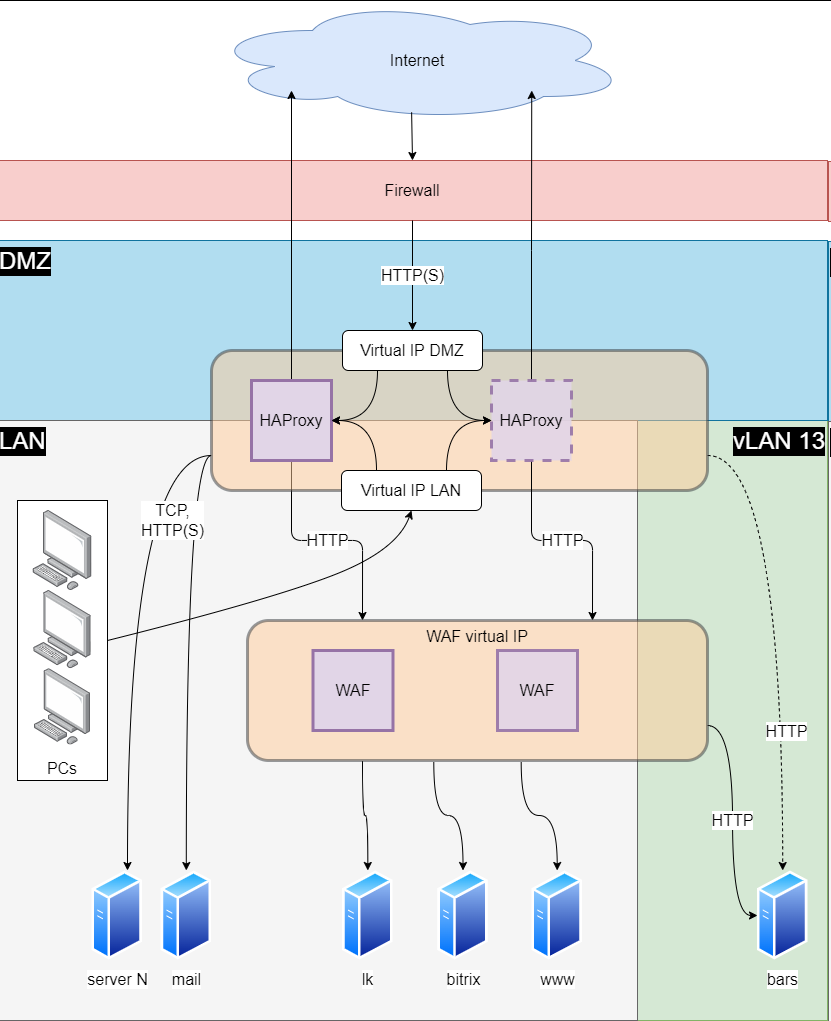
Виртуальные IP для HAProxy обеспечивает Keepalived. Суть в том, что клиенты обращаются не на реальный адрес сервера реверс-прокси/балансировщика, а на виртуальный, привязанный к сетевым адаптерам нескольких серверов. Трафик идёт на адаптер того сервера, который имеет наибольший вес. Если сервер не отвечает, то трафик начинает идти на другой сервер, привязанный к тому же виртуальному IP. Виртуальных IP-адреса я сделал два, так как балансировщик обслуживает и внутренних клиентов, обращающихся на внутренние же ресурсы.
У Keepalived обнаружилась отличная функция: трафик переключается на резервный сервер не только когда основной недоступен целиком, но и когда на нём перестаёт работать служба HAProxy. Вот кусок конфигурации /etc/keepalived/keepalived.conf:
vrrp_script chk_haproxy {
script "/usr/bin/killall -0 haproxy"
interval 3
weight 50
}
vrrp_instance haproxy_DMZ {
interface eth2
virtual_router_id 1
priority 100
authentication {
auth_type PASS
auth_pass verySecretPasswordHere
}
virtual_ipaddress {
192.168.1.100/24
}
track_script {
chk_haproxy
}
# smtp_alert
}
В данном случае к приоритету virtual_router_id добавляется 50, если служба работает. На первом сервере начальный приоритет 100, на втором — 90, соответственно, при работающей службе HAProxy на обоих серверах это 150 и 140. Когда на первом сервере служба перестаёт работать, то общий вес становится 100 и трафик начинает идти на второй сервер. При восстановлении работы службы на первом сервере всё возвращается в исходное состояние. Keepalived ещё умеет слать письма при изменении статуса, но он меня так заваливал письмами во время отладки, что я отключил это дело, тем более, что позже я настроил балансировку почтового трафика Exchange, SMTP-порт стал занятым и просто так слать письма с сервера реверс-прокси уже не получалось в любом случае, поэтому я просто удалил Postfix и занялся другими вещами, к тому же, переключение и так работает без проблем.
Теперь, собственно, о HAProxy. Основные источники информации — блог на haproxy.com с меткой Basics, статья там же о защите от DDoS-атак и, конечно, документация. Что я там вкратце реализовал:
- HTTPS-соединение идёт только по протоколам TLS 1.2 и TLS 1.3, на этот счёт есть очень удобный Mozilla SSL Configuration Generator.
- Разрешены только HTTP/1.1 и HTTP/2.0.
- Запрещены подключения без указания имён хостов (кроме почтовых URL).
- Если IP создаёт больше 480 соединений за минуту или запрашивает один и тот же URL (часть до знака вопроса) больше 30 раз за 30 секунд, то ему выдаётся код 429 Too many requests (см. статью Introduction to HAProxy Stick Tables). Исключение — внутренние сети компании.
- Запрещено обращение на URL, где после наклонной черты идёт точка, например, https://example.com/site/.default, за некоторыми исключениями.
- Всё, кроме нескольких исключений, перенаправляется на HTTPS.
- Перенаправления, выбор бэкендов, исключения из HTTPS, чёрные списки реализованы с помощью карт и списков доступа.
С переводом трафика Exchange через реверс-прокси возникли некоторые сложности — оказалось, что Outlook на Windows 7 не может подключиться к почтовому серверу, так как на старых ОС используются устаревшие протоколы шифрования, которые на моём HAProxy запрещены. Нужно ставить патч KB3140245 и править реестр (или ставить MicrosoftEasyFix51044), после этого всё работает нормально.
Также, для Outlook на HAProxy пришлось добавить список заголовков, так как без него Outlook не желал устанавливать соединение с сервером. Я вынес заголовки с отдельный файл и добавил их в /etc/haproxy/haproxy.cfg, после этого всё завелось:
global
h1-case-adjust-file /etc/haproxy/headers.list
frontend fe_web
bind :80
bind :443 ssl crt /etc/ssl/certs/example alpn h2,http/1.1
option h1-case-adjust-bogus-client # for Outlook clients
Другая проблема не решена до сих пор — при отправке писем скриптами из Powershell они не доходят до получателя, при этом в логах HAProxy сказано, что соединение неожиданно прервал клиент на этапе передачи данных. При этом, 1С отправляет письма без проблем. Пока приходится указывать в скриптах прямой адрес почтового сервера или править файл hosts.
В целом всё было настроено, кроме мониторинга, и я в рабочее время посматривал на таблицу соединений, чтобы примерно определить разумные пороги блокировок, когда в среду 13 апреля началась DDoS-атака:

В минуту было свыше миллиона запросов, заметная их часть использовала протокол HTTP неведомой версии 1.2 и такой же непонятный HTTP-метод ST. Все эти запросы всё равно не достигали цели, так как сильно превышали лимит подключений в минуту, HTTP/1.2 и так был запрещён, а метод ST я тут же поспешил заблокировать, так что до нижестоящих серверов этот вал не доходил и, в принципе, можно было оставить так и ждать, когда атака выдохнется, но всплыл неожиданный нюанс — так как всё это записывалось в логи, место на диске заканчивалось примерно за полдня. Стало понятно, что нужно ставить fail2ban для динамической блокировки IP-адресов с помощью встроенного линуксового файрволла netfilter, потому что чистить логи и переключаться с сервера на сервер вручную — занятие довольно нелепое.
Fail2ban — очень остроумная штука. Он смотрит в указанный лог и считает количество определённых строк, заданных регулярным выражением — например, сообщение об ошибке после неправильно введённого пароля — и если количество этих ошибок превышает заданное количество за отведённое время (положим, 5 неправильно набранных паролей за 10 минут), то fail2ban создаёт запрещающее правило на файрволле для IP-адреса этого клиента на заданное время (допустим, на 3 часа). По прошествии этого времени запрет снимается, и клиент опять может загрузить страницу и пытаться войти.
Настроив fail2ban, я с удивлением обнаружил, что блокировать адреса-то он начинает, но через короткое время по непонятной причине перестаёт это делать. Оказалось, что не я один столкнулся с такой проблемой, когда fail2ban просто не успевает обрабатывать эту Ниагару из логов, и я последовал советам — во-первых, установить самую свежую версию fail2ban вручную, так как версия в стандартных репозиториях отставала, а во-вторых, использовать nftables (интерфейс управления netfilter) вместо стандартного iptables, так как nftables быстрее. Получились такие настройки:
### /etc/fail2ban/filter.d/haproxy-ddos.conf ###
[INCLUDES]
before = common.conf
[Definition]
failregex = ^%(__prefix_line)s<ADDR>:\\d+.\*?\\sPR--\\s.\*$
ignoreregex = ^%(__prefix_line)smessage repeated
### /etc/fail2ban/jail.local ###
[DEFAULT]
ignoreip = 127.0.0.0/8 10.0.0.0/8 172.16.0.0/12 192.168.0.0/16 ::1
banaction = nftables-multiport
banaction_allports = nftables-allports
[haproxy-ddos]
enabled = true
filter = haproxy-ddos
logpath = /var/log/haproxy.log
bantime = 6h
findtime = 1m
maxretry = 100
Вдобавок, я решил помочь fail2ban простеньким скриптом, срабатывающим каждую минуту — вывод списка адресов из таблицы HAProxy, которые генерируют пятизначные числа запросов и более, и сразу добавлять их в «тюрьму» fail2ban. Менее наглых он уже пристрелит сам.
for ip in $(echo "show table st_per_ip_rate" |socat stdio /var/run/haproxy/admin.sock |egrep "[0-9]{5}$" |cut -d '=' -f 2 |cut -d ' ' -f 1)
do
fail2ban-client set haproxy-ddos banip $ip
done
После этого всё пошло как по маслу. Едва появившись, участники ботнета сразу же блокировались, логи перестали забивать диск и атака уже никак не влияла на работу системы. На пике было заблокировано немногим менее 5000 адресов.


Атака продлилась до вечера воскресенья 17 апреля, и к утру понедельника все адреса были автоматически разблокированы.
Через некоторое время я настроил мониторинг:

Напоследок расскажу про сертификаты SSL. Одна из очень удобных вещей в HAProxy — автоматический выбор сертификатов. Просто указываешь в секции frontend каталог, где они лежат, и при заходе на сайт подключается подходящий действующий сертификат, просроченные игнорируются.
frontend fe_https
bind :443 ssl crt /etc/ssl/certs/haproxy alpn h2,http/1.1
Так как, в числе прочего, сейчас имеются проблемы с выпуском коммерческих SSL-сертификатов и время ожидания их выпуска увеличилось до месяца, то на днях возникла ситуация, когда срок действия сертификата на одном из сайтов истёк, а новый ещё не был выпущен. Решение проблемы — Let’s Encrypt, который в России пока ещё работает, но так как порты 80 и 443 уже заняты, Certbot (агент Let’s Encrypt по выпуску и обновлению сертификатов) должен работать на другом порту, для чего нужно настроить HAProxy:
# На фронтенде :80
# Let's Encrypt URL
acl letsencrypt_url path_beg /.well-known/acme-challenge/
# Не пробрасывать на HTTPS
http-request redirect scheme https if !{ ssl_fc } !no-https-domains !letsencrypt_url
# Бэкенд Let's Encrypt
use_backend be_letsencrypt if letsencrypt_url
# Бэкенд
backend be_letsencrypt
server letsencrypt 127.0.0.1:54321
После этого, установив Certbot, как рекомендуют, из пакета snap, выпускаем сертификат:
certbot certonly --standalone --preferred-challenges http-01 --http-01-port 54321 --keep --agree-tos --expand -m ssl@example.com -d example.com -d www.example.com
Saving debug log to /var/log/letsencrypt/letsencrypt.log
Requesting a certificate for example.com and www.example.com
Successfully received certificate.
Certificate is saved at: /etc/letsencrypt/live/example.com/fullchain.pem
Key is saved at: /etc/letsencrypt/live/example.com/privkey.pem
This certificate expires on 2022-08-18.
These files will be updated when the certificate renews.
Certbot has set up a scheduled task to automatically renew this certificate in the background.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
If you like Certbot, please consider supporting our work by:
* Donating to ISRG / Let`s Encrypt: https://letsencrypt.org/donate
* Donating to EFF: https://eff.org/donate-le
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
В принципе, всё, дальше Certbot будет сам обновлять сертификат, запуская периодические проверки, запланированные не в стандартном cron, а в systemd timers (отдельная интересная тема). Теперь осталось слепить сертификаты и закрытые ключи для использования в HAProxy:
#!/bin/bash
LE_CERT_DIR=/etc/letsencrypt/live
HAPROXY_CERT_DIR=/etc/ssl/certs/haproxy
# Cat the certificate chain and the private key together for haproxy
for path in $(find $LE_CERT_DIR/* -type d -exec basename {} \;); do
cat $LE_CERT_DIR/$path/{fullchain,privkey}.pem > $HAPROXY_CERT_DIR/${path}.pem
done
До автоматизации создания готовых сертификатов для HAProxy и перечитывания его конфигурации для применения изменений руки пока не дошли, но я займусь этим в ближайшее время. В Certbot есть опция --deploy-hook, возможно, лучше всего работать с помощью неё.
На этом пока всё. Конечно, моя конфигурация неидеальна как с точки зрения архитектуры и безопасности, так и с практической стороны — нужно синхронизировать конфигурацию между узлами Haproxy, желательно передавать статус fail2ban на сервер-партнёр, а теперь ещё и синхронизировать сертификаты SSL. Тем не менее, сегодняшнее положение вещей гораздо лучше, чем то, с чего этот рассказ начинался.
WAF разработчики переустановили и настроили, теперь он тоже кластеризован, и трафик на него балансируется с HAProxy. А веб-сервер с сайтами тоже подновлён, насколько это возможно — переехали с помощью коллег на Ubuntu 14.04, более свежую ОС не позволяет ставить древняя система управления контентом, не работающая с PHP новее 5-й версии, но это хотя бы даёт совместимый с Hyper-V гигабитный сетевой интерфейс, который уже не виснет на ровном месте и не тормозит, так что всё к лучшему.
Всем добра и мирного неба!


")


