Долго не мог себя заставить что-то написать, но надо, а то забывается всё.
Построил два кластера Hyper-V
Базой послужили сервера, которые освободились в результате виртуализации сервисов, которые на них крутились, занимая в среднем 10% от их мощности. Теперь появилась возможность использовать ресурсы более рационально и добавить отказоустойчивости.
Первый кластер — продуктивный на немолодых, но вполне боеспособных серверах HP Proliant 380DL Gen8. Сейчас три узла, на каждом по 192 ГБ памяти, планируется ещё два добавить в следующем году, когда для них докупят память и серверные лицензии. В качестве ОС выступает Windows Server 2019 Datacenter. Подключены полки HP P2000 и NetApp AFF-220 с флеш-массивом.
Второй — тестовый на более новых ProLiant DL380 Gen9 — их всего два, поэтому продуктив на них строить нет смысла. ОС — бесплатная Windows Hyper-V Server 2019. Подключена вторая полка HP P2000. Там крутится всё тестовое барахло, которое не нужно резервно копировать.
PS C:\> get-vm -ComputerName (Get-ClusterNode -Cluster hvc)
Name State CPUUsage(%) MemoryAssigned(M) Uptime Status Version
---- ----- ----------- ----------------- ------ ------ -------
t-docker1 Running 0 4096 5.22:48:09.8380000 Работает нормально 9.0
t-sql2017-1 Running 0 8192 5.22:48:27.3800000 Работает нормально 9.0
t-w10-1 Off 0 0 00:00:00 Работает нормально 9.0
t-w7-2 Off 0 0 00:00:00 Работает нормально 9.0
t-w7-3 Off 0 0 00:00:00 Работает нормально 9.0
vmls-bpm-exch Running 0 4096 5.22:47:09.9290000 Работает нормально 9.0
vmls-haproxy1 Off 0 0 00:00:00 Работает нормально 9.0
vmls-jibri1 Running 0 4096 5.22:48:16.5620000 Работает нормально 9.0
vmls-jitsi1 Running 0 16384 5.22:47:28.6320000 Работает нормально 9.0
vmls-lk-test Running 0 4096 5.22:49:02.0820000 Работает нормально 9.0
vmws-trueconf1 Running 0 8192 5.22:47:28.2950000 Работает нормально 9.0
t-w11-1 Running 0 4096 5.22:13:14.2280000 Работает нормально 9.0
vmls-jibri2 Off 0 0 00:00:00 Работает нормально 9.0
vmls-jibri3 Off 0 0 00:00:00 Работает нормально 9.0
vmls-jibri4 Off 0 0 00:00:00 Работает нормально 9.0
vmls-jibri5 Off 0 0 00:00:00 Работает нормально 9.0
vmus-wp Running 0 2048 5.22:13:49.3510000 Работает нормально 9.0
web2-dev2 Running 0 2048 5.22:13:49.2880000 Работает нормально 9.0
Что интересно, на некоторых серверах Gen8 кэш RAID-контроллера показывался в мониторинге как сбойный, вылечилось обновлением прошивки.
Освободилась куча жёстких дисков: так как все виртуалки теперь хранятся на полках и место на нодах нужно только для операционной системы и установочных образов, я пересоздал на всех серверах локальное хранилище, сделав там RAID1 + spare, а лишние диски выдернул. Теперь запас на замену солидный.
С течением времени Hyper-V мне нравится всё больше — мало того, что можно виртуальные машины переносить между нодами даже без наличия кластера, кластеры создавать на базе бесплатного Hyper-V Server и для его функционирования не нужен никакой платный управляющий сервер, как в случае с VMware, так с 2016 версии там появилась автобалансировка нагрузки, что для компаний малого и среднего размера делает фактически ненужными инструменты типа Virtual Machine Manager. В принципе, даже без этого механизма примитивный балансировщик можно написать и самому, благо, Hyper-V прекрасно управляется через Powershell.
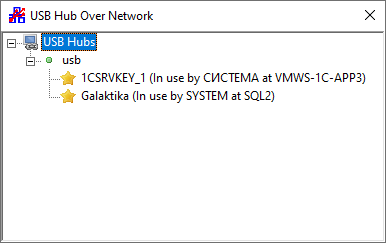
В следующем году, если всё будет нормально, купят ещё и устройство проброса USB-токенов по сети, тогда можно будет перенести последний бастион VMware 5.5, где живёт 1С и ему подобные вещи. Логично было бы, конечно, заняться конвертацией лицензий в электронные, но не всё возможно конвертировать, а в случае 1С имеется некое антропогенное сопротивление.
Теперь обновлять ноды кластера можно прямо посреди рабочего дня:
Suspend-ClusterNode -Name "node1" -Drain
Resume-ClusterNode -Name "node1" -Failback Immediate
С кластеростроением связано и то, что я
Прошил SAN-свитчи
Началось с того, что после подключения к кластеру новой модной флеш-полки NetApp и перенесения туда некоторого количества виртуалок, в один прекрасный день решили обновить ноды, и после перезагрузки последней из них все виртуальные машины, лежащие на этой полке, потеряли свои жёсткие диски. Вторая полка — Хьюлет Паккард — продолжала работать как ни в чём не бывало. Началась паника, в результате после перезагрузки SAN-свитчей всё восстановилось.
Обнаружилось, что после перезагрузки кластерной ноды полка перестаёт эту ноду видеть. Дело в том, что NetApp использует виртуальный WWN, и, скорее всего, SAN-свитчи HP 8/8 с древней прошивкой v7.0.0c не вполне корректно с этим делом работают. Я предложил прошить их до максимально возможной версии, что после одобрения руководства и проделал. На своей рабочей машине я развернул FTP-сервер и прошил оба свитча в такой последовательности: v7.0.0c → v7.0.2e1 → v7.1.2b1 → v7.2.1g → v7.3.2b → v7.4.2d. Шить надо последовательно, прибавляя единицу ко второй цифре. Первую итерацию перестраховался, прошив до последней доступной мне версии в рамках одной и той же второй цифры.

Моё предположение оказалось верным — после прошивки всё заработало как нужно, полка перестала терять хосты после их перезагрузки.
Написал скрипт контроля домашних каталогов пользователей
Два года назад я уже делал отчёт по домашним каталогам, теперь пришло время навести порядок с этим делом. Внезапно выяснилось, что групповой политики создания каталогов не было, поэтому при создании учётки и прописывании пути к каталогу он не создавался. Раньше это делали, как и всё остальное, руками, поэтому были ошибки в именах каталогов, права на папки были розданы невесть как, при выключении учётки каталог никуда не девался и продолжал валяться в общей куче, при переименовании логина пользователя каталог оставался со старым именем — в общем, бардак.
Конечно, можно было бы создать групповую политику, но она бы не учитывала всего того, что уже навертели, как и, например, смену логина, поэтому хотелось сделать что-то погибче.
После некоторых умственных борений, проб и ошибок я пришёл к такой логике: пляшем от того, что каталог может быть либо прописан, либо не прописан в учётной записи пользователя.
Если он прописан, он может:
- Не совпадать с логином, и корректной папки не существует, но при этом есть та, которая прописана — тогда нужно переименовать текущую папку, а путь скорректировать.
- Не совпадать с логином, и папки по прописанному пути не существует, но корректная папка существует — скорректировать путь.
- Не совпадать с логином, но существуют и корректная папка, и неправильная — написать человеку, чтобы разобрался.
- Не совпадать с логином, но не существует ни той папки, что прописана, ни корректной — создать и прописать правильный каталог.
- Совпадать с логином, но каталога не существует — создать каталог.
Если домашний каталог не прописан:
- Если есть папка, совпадающая с логином — прописать её.
- Если папки нет — создать её и прописать в учётку.
Также, скрипт смотрит в список прав на каталоги (с помощью прекрасного модуля NTFSSecurity), и если там явно заданных (неунаследованных) прав больше единицы или в списке отсутствует логин пользователя — сбрасывает разрешения на каталог и задаёт полные права для одного пользователя. Какие разрешения были — на всякий случай сообщается человеку.
В итоге, я получаю подобные письма:
Алексеев Олег Владимирович: не был настроен диск Z, создана и прописана папка (Alekseevov).
Анциферова Ольга Николаевна: переименована папка диска Z для соответствия с логином: Rumyanceva → antsiferovaon
В папке Rumyanceva были выставлены неверные явные разрешения - их 4, выданы BUILTIN\Администраторы, DOMAIN\antsiferovaon
Внукова Валентина Геннадьевна: прописанная папка диска Z (vnukovavg) не существовала и была создана.
Горбунова Ирина Васильевна: прописанной папки диска Z не существует (Berdisheva), но существует совпадающая с логином (Gorbunova). Путь скорректирован.
Петрова Юлия Сергеевна: прописанная папка диска Z (petrovayus) не совпадала с логином (petrovays), но так как обоих каталогов не существовало, был создан и прописан правильный.
Фанова Ирина Анатольевна: прописанная папка диска Z (Fanovaia) не совпадает с логином (Fanova), но существуют оба каталога. Необходимо разобраться.
А тот ежемесячный отчёт двухгодичной давности я дополнил механизмом архивации каталогов отключенных или отсутствующих пользователей или удаления, если каталог пустой. Об этом теперь мне сообщается так:
Лишний каталог Abramian пуст и был удалён.
Лишний каталог Afanasieva перенесён в архив (3 файла, 0.35 МБ).
Лишний каталог Ageenko перенесён в архив (5 файлов, 0.92 МБ).
Лишний каталог Akimova пуст и был удалён.
Лишний каталог Aksenov пуст и был удалён.
Лишний каталог Alekseeva перенесён в архив (3 файла, 1.45 МБ).
Лишний каталог Alekseevmv пуст и был удалён.
Лишний каталог Alexandrov перенесён в архив (2795 файлов, 755.9 МБ).
Теперь система сама следит за порядком в домашних каталогах, красота.
Настроил единый вход (SSO) для DokuWiki
Памятуя об успехе настройки Squid и прочитав, что DokuWiki также имеет механизм работы с Active Directory и Single sign-on, решил реализовать это на практике. Ведь очень удобно, когда открываешь страницу wiki и сразу авторизуешься под своей учёткой с соответствующими правами.
Делал как и раньше в случае со Сквидом — через keytab-файл, только в этом случае пароль делал случайный, потому что нет никакого смысла задавать его извне — вводить этот пароль никуда не придётся. Перенёс keytab на сервер wiki, настроил /etc/krb5.conf. Далее нужно настраивать саму DokuWiki.
/var/www/html/conf/local.php
<?php
$conf['title'] = 'Wiki';
$conf['lang'] = 'ru';
$conf['license'] = '0';
$conf['superuser'] = '@wiki-admins';
$conf['target']['interwiki'] = '_blank';
$conf['target']['extern'] = '_blank';
$conf['userewrite'] = '1';
$conf['useslash'] = 1;
/var/www/html/conf/local.protected.php
$conf['useacl'] = 1;
$conf['authtype'] = 'authad';
$conf['disableactions'] = 'register';
$conf['plugin']['authad']['account_suffix'] = '@domain.ru';
$conf['plugin']['authad']['base_dn'] = 'DC=domain,DC=ru';
$conf['plugin']['authad']['domain_controllers'] = 'DC1.domain.ru,DC2.domain.ru,DC3.domain.ru';
$conf['plugin']['authad']['domain'] = 'domain.ru';
$conf['plugin']['authad']['recursive_groups'] = 1;
$conf['plugin']['authad']['sso'] = 1;
$conf['plugin']['authad']['ad_username'] = 'wiki-admin';
$conf['plugin']['authad']['ad_password'] = 'P@ssw0rd';
Потом Apache.
# Для начала надо установить модуль для Kerberos:
apt install libapache2-mod-auth-gssapi
# И настроить его в /etc/apache2/apache2.conf
<Directory "/var/www/html">
AuthType GSSAPI
AuthName "GSSAPI Wiki SSO"
GssapiBasicAuth On
Require valid-user
</Directory>
# Чтобы не парить людям мозги насчёт необходимости набирать полное имя
# wiki.domain.ru вместо просто wiki (это необходимо для работы SSO), делаем редирект.
# /etc/apache2/sites-available/000-default.conf
<If "%{HTTP_HOST} != 'wiki.domain.ru'">
Redirect "/" "http://wiki.domain.ru/"
</If>
Ну, а дальше можно создавать в AD группы, включать туда пользователей и раздавать для этих групп права на соответствующие разделы и страницы.
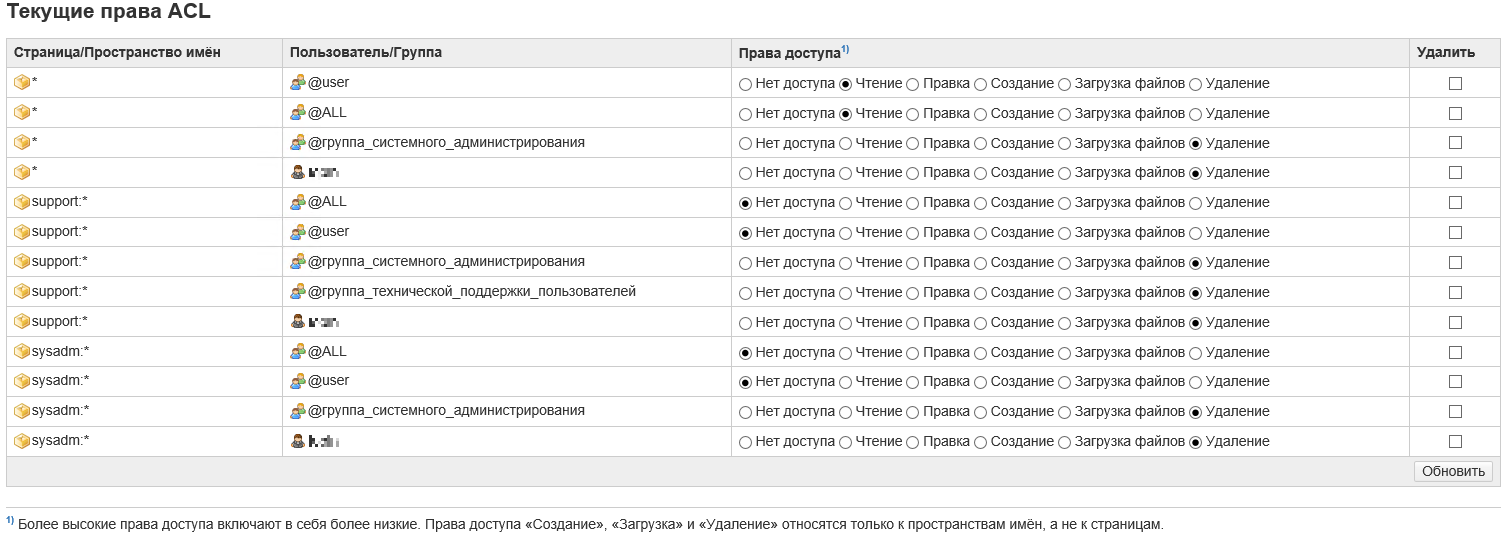
 Последнее действие перед выключением
Последнее действие перед выключением