Попался мне один DVD-Video с концертом, который надо было перекодировать в более компактный и удобный формат. Сегодня это H.265 (HEVC) для видео и OPUS для аудиодорожки. Также, хотелось бы иметь удобную навигацию, то есть, возможность перематывать сразу на начало следующего номера. Для этого необходимо вытащить с DVD метаданные и переделать их в формат, понятный кодировщику ffmpeg. Сразу скажу, что с метаданными-то и возникли проблемы, которые нужно было решить. Всё действие будет происходить в командной строке Powershell. Поехали.
DVD имел стандартный вид — это папка VIDEO_TS с файлами IFO, где хранится меню, и VOB, где содержится видео в формате MPEG-2, порезанное на части по гигабайту. Полезные файлы VOB имеют индекс VTS_<номер видео>_<номер файла>.VOB, где номера начинаются с единицы. Например, такими файлами будут VTS_01_1.VOB, VTS_01_2.VOB и так далее, или VTS_02_1.VOB, VTS_02_2.VOB и так далее. Их можно легко вычислить по большому размеру (столбец Length):
cd "C:\temp\PETERSON_QUARTET\VIDEO_TS"
dir -Recurse -Include "*.ifo","*.vob"
Directory: C:\temp\PETERSON_QUARTET\VIDEO_TS
Mode LastWriteTime Length Name
---- ------------- ------ ----
-ar-- 01.04.2025 10:01 16384 VIDEO_TS.IFO
-ar-- 01.04.2025 10:01 1198080 VIDEO_TS.VOB
-ar-- 01.04.2025 10:01 40960 VTS_01_0.IFO
-ar-- 01.04.2025 10:01 149504 VTS_01_0.VOB
-ar-- 01.04.2025 11:10 1073664000 VTS_01_1.VOB
-ar-- 01.04.2025 11:10 1054126080 VTS_01_2.VOB
-ar-- 01.04.2025 10:01 43008 VTS_02_0.IFO
-ar-- 01.04.2025 10:01 149504 VTS_02_0.VOB
-ar-- 01.04.2025 11:10 1073295360 VTS_02_1.VOB
-ar-- 01.04.2025 11:10 1073457152 VTS_02_2.VOB
-ar-- 01.04.2025 11:05 228806656 VTS_02_3.VOB
Сразу займёмся метаданными. Нужно сказать, что меню DVD-Video могут иметь самую причудливую и неудобную для обработки структуру. Раньше для вытаскивания пунктов меню из файлов IFO я пользовался программой ChapterXtractor, для которой я сделал шаблон, сразу при сохранении создающий файл метаданных ffmpeg с пересчётом временных меток. Но когда я открыл файлы VTS_01_0.IFO и VTS_02_0.IFO, стало ясно, что здесь так сделать не выйдет.


Как видно из картинок, каждое меню содержит полный набор номеров, но часть из них очень короткие, то есть, это явно заглушки. Само меню на DVD двухстраничное, что, наверное, и обусловило наличие двух меню вместо одного. Концерт на DVD один, поэтому эти два меню нужно как-то совмещать.


Для этого я взял консольную программу vgtmpeg, которая представляет собой видоизменённый ffmpeg, дополненный инструментами по работе с DVD/BluRay и т. п. В частности, эта программа умеет показывать метаданные DVD и даже конвертировать их сразу в формат ffmpeg, но сейчас это нам не подходит, так как нужна предварительная обработка. Вот информация, которую vgtmpeg выдаёт об этом диске:
$vgtmpeg = & C:\scripts\vgtmpeg\vgtmpeg.exe -hide_banner -i 'dvd://.' 2>&1
# Вывести результат
$vgtmpeg
Guessed Channel Layout for Input Stream #0.1 : stereo
Input #0, mpeg, from 'dvd://.?title=1':
Metadata:
source_type : dvd
Duration: 00:42:15.18, start: 0.000000, bitrate: 6714 kb/s
Chapter #0:0: start 0.000000, end 513.689289
Chapter #0:1: start 513.689289, end 989.563244
Chapter #0:2: start 989.563244, end 1420.233467
Chapter #0:3: start 1420.233467, end 1768.811800
Chapter #0:4: start 1768.811800, end 2132.419356
Chapter #0:5: start 2132.419356, end 2533.942333
Chapter #0:6: start 2533.942333, end 2534.118556
Chapter #0:7: start 2534.118556, end 2534.294778
Chapter #0:8: start 2534.294778, end 2534.471000
Chapter #0:9: start 2534.471000, end 2534.647222
Chapter #0:10: start 2534.647222, end 2534.823444
Chapter #0:11: start 2534.823444, end 2534.999667
Chapter #0:12: start 2534.999667, end 2535.175889
Program 1
Stream #0:0[0x100e0]: Video: mpeg2video (Main), yuv420p(tv, top first), 720x480 [SAR 8:9 DAR 4:3], 29.97 fps, 29.97 tbr, 90k tbn, 59.94 tbc
Stream #0:1[0x100a0](und): Audio: pcm_dvd, 48000 Hz, stereo, s16, 1536 kb/s
Metadata:
language-iso639_2: und
language-simple : Unknown
language-description: Unknown
No Program
Stream #0:2[0x100bf]: Data: dvd_nav_packet
Guessed Channel Layout for Input Stream #1.1 : stereo
Input #1, mpeg, from 'dvd://.?title=2':
Metadata:
source_type : dvd
Duration: 00:45:33.19, start: 0.000000, bitrate: 6953 kb/s
Chapter #1:0: start 0.000000, end 0.176222
Chapter #1:1: start 0.176222, end 0.352444
Chapter #1:2: start 0.352444, end 0.528667
Chapter #1:3: start 0.528667, end 0.704889
Chapter #1:4: start 0.704889, end 0.881111
Chapter #1:5: start 0.881111, end 1.057333
Chapter #1:6: start 1.057333, end 388.582222
Chapter #1:7: start 388.582222, end 712.003578
Chapter #1:8: start 712.003578, end 1017.434489
Chapter #1:9: start 1017.434489, end 1419.978933
Chapter #1:10: start 1419.978933, end 1858.760578
Chapter #1:11: start 1858.760578, end 2302.571778
Chapter #1:12: start 2302.571778, end 2733.185778
Program 2
Stream #1:0[0x200e0]: Video: mpeg2video (Simple), yuv420p(tv, top first), 720x480 [SAR 8:9 DAR 4:3], 29.97 fps, 29.97 tbr, 90k tbn, 59.94 tbc
Stream #1:1[0x200a0](und): Audio: pcm_dvd, 48000 Hz, stereo, s16, 1536 kb/s
Metadata:
language-iso639_2: und
language-simple : Unknown
language-description: Unknown
No Program
Stream #1:2[0x200bf]: Data: dvd_nav_packet
At least one output file must be specified
Отлично, всё видно. Нужные строки — со словом chapter. Сделаем из них таблицу и вычислим длительность частей в дополнительной колонке.
$csv = $vgtmpeg -match 'chapter' -replace '.*#(\d+:\d+).*start ([\d\.]+).*end ([\d\.]+)','$1;$2;$3' |
ConvertFrom-Csv -Header Chapter,Start,End -Delimiter ';' |
select *,@{n='Range';e={$_.End - $_.Start}}
# Вывести результат
$csv
Chapter Start End Range
------- ----- --- -----
0:0 0.000000 513.689289 513,69
0:1 513.689289 989.563244 475,87
0:2 989.563244 1420.233467 430,67
0:3 1420.233467 1768.811800 348,58
0:4 1768.811800 2132.419356 363,61
0:5 2132.419356 2533.942333 401,52
0:6 2533.942333 2534.118556 0,18
0:7 2534.118556 2534.294778 0,18
0:8 2534.294778 2534.471000 0,18
0:9 2534.471000 2534.647222 0,18
0:10 2534.647222 2534.823444 0,18
0:11 2534.823444 2534.999667 0,18
0:12 2534.999667 2535.175889 0,18
1:0 0.000000 0.176222 0,18
1:1 0.176222 0.352444 0,18
1:2 0.352444 0.528667 0,18
1:3 0.528667 0.704889 0,18
1:4 0.704889 0.881111 0,18
1:5 0.881111 1.057333 0,18
1:6 1.057333 388.582222 387,52
1:7 388.582222 712.003578 323,42
1:8 712.003578 1017.434489 305,43
1:9 1017.434489 1419.978933 402,54
1:10 1419.978933 1858.760578 438,78
1:11 1858.760578 2302.571778 443,81
1:12 2302.571778 2733.185778 430,61
Вот, стало гораздо лучше. В колонке Range числа хранятся точные, просто при выводе всей таблицы отображаются в сокращённом виде. Например, если вывести второе значение отдельно, то оно будет 475,873955, так что по поводу корректности расчётов можно не беспокоиться. Теперь наглядно видно, что первые 6 частей берутся из первого меню, а последующие — из второго. Из-за того, что начала и окончания частей не идут последовательно по времени, надо их реконструировать. Для этого я взял первую метку начала и дальше прибавлял к ней длину из Range, а потом отсеивал те части, которые меньше 5 секунд.
$timeline = @()
$t = $csv[0].Start
$csv |% {
$obj = [PSCustomObject]@{
Start = $t
End = $t + $_.Range
Range = $_.Range
}
$t = $t + $_.Range
$timeline += $obj |? Range -gt 5
}
# Вывести результат
$timeline
Start End Range
----- --- -----
0,00 513,69 513,69
513,69 989,56 475,87
989,56 1420,23 430,67
1420,23 1768,81 348,58
1768,81 2132,42 363,61
2132,42 2533,94 401,52
2536,23 2923,76 387,52
2923,76 3247,18 323,42
3247,18 3552,61 305,43
3552,61 3955,15 402,54
3955,15 4393,94 438,78
4393,94 4837,75 443,81
4837,75 5268,36 430,61
# Показать количество строк
$timeline.count
13
Прекрасно! Ровно 13 частей. Можно теперь лепить файл метаданных ffmpeg.
# Названия частей
$titles = ("Cakewalk
Love Ballade
Soft Winds
You Look Good To Me
My One And Only Love
Nigerian Market Place
Cool Walk
I Can't Get Started
Come Sunday
Reunion Blues
If You Only Knew
Sushi Blues
Blues Etude") -split "`n"
# Создание нового файла метаданных file.ffmeta для ffmpeg, заголовок
";FFMETADATA1
title=Recorded 'LIVE' at Kan-i Hoken Hall, Tokyo on February 28, 1987
artist=Oscar Peterson Featuring Joe Pass - The Quartet Live
" > file.ffmeta
# Добавление частей с названиями, переделка времени в миллисекунды
$c = 0
$timeline |% {
"[CHAPTER]
TIMEBASE=1/1000
START=$($_.start.tostring("0.000") -replace '\D')
END=$($_.end.tostring("0.000") -replace '\D')
title=$($titles[$c])
"
$c++
} >> file.ffmeta
Сначала я округлял число до тысячных: [Math]::Round($_.start, 3), и получил вроде бы правдоподобный результат, но выяснилось, что если последней цифрой после запятой оказывался 0, то он, естественно, пропадал и ffmpeg при попытке вшить эти метаданные в видеофайл выдавал ошибку, так как такая метка была на один десятичный разряд меньше и оказывалась по времени раньше предыдущей. Поэтому задействовал .tostring("0.000"), что гарантировало корректный перевод в строку.
Фрагмент полученного файла file.ffmeta:
;FFMETADATA1
title=Recorded 'LIVE' at Kan-i Hoken Hall, Tokyo on February 28, 1987
artist=Oscar Peterson Featuring Joe Pass - The Quartet Live
[CHAPTER]
TIMEBASE=1/1000
START=0000
END=513689
title=Cakewalk
[CHAPTER]
TIMEBASE=1/1000
START=513689
END=989563
title=Love Ballade
[CHAPTER]
TIMEBASE=1/1000
START=989563
END=1420233
title=Soft Winds
С метаданными разобрались, теперь дело за перекодировкой. Параметры -analyzeduration 100M -probesize 100M нужны, чтобы увеличить глубину определения аудиопотоков, потому что без них ffmpeg иногда не видел в DVD аудиодорожку. На вход подаются все файлы VOB, склеенные через concat: по порядку, и файл file.ffmeta как метаданные.
DVD-Video — старый формат, и видео там чересстрочное (interlaced), когда кадр делится на полукадры — «поля» (fields) — которые выводятся на экран последовательно. Раньше я всегда оставлял чересстрочную развёртку, когда кодировал в H.264 (AVC), потому что качество работы фильтров деинтерлейса тогда часто вызывало вопросы. H.265 тоже вроде как-то поддерживает чересстрочное видео, но cмысла заниматься этой экзотикой сегодня я не вижу, потому что найден прекрасный фильтр деинтерлейса bwdif. Оказалось, что наилучшие результаты деинтерлейса достигаются при удвоении частоты кадров — видео получается плавное и никакой «гребёнки» и «теней» в кадре не наблюдается. Фильтр сам умеет определять порядок полей, так что в большинстве случаев никаких настроек не требуется. А то, что видео получается 60 кадров/сек, сегодня уже не проблема.
Мой процессор поддерживает аппаратное кодирование в H.265, поэтому используется кодировщик hevc_qsv, качество 26 (настройка в сторону лучшего качества, чем стандартные 28 в софт-варианте libx265), хотя можно поставить, к примеру, и 24, если источник шумный. Звуковой кодек — libopus, 192 кбит/сек, чего вполне достаточно для любого стереосигнала. Тэг-идентификатор формата видео я ставлю по старой памяти; полагаю, можно обойтись и без него.
ffmpeg -analyzeduration 100M -probesize 100M `
-i "concat:VTS_01_1.VOB|VTS_01_2.VOB|VTS_02_1.VOB|VTS_02_2.VOB|VTS_02_3.VOB" -i file.ffmeta `
-vf bwdif -c:v hevc_qsv -c:a libopus -b:a 192k `
-global_quality:v 26 -tag:v hvc1 "Oscar Peterson - The Quartet Live (1987).mp4"
Результат: конечный файл занимает 655 МБ против 4,2 ГБ у исходного DVD. Качество никак не пострадало, заголовки и навигация на месте.
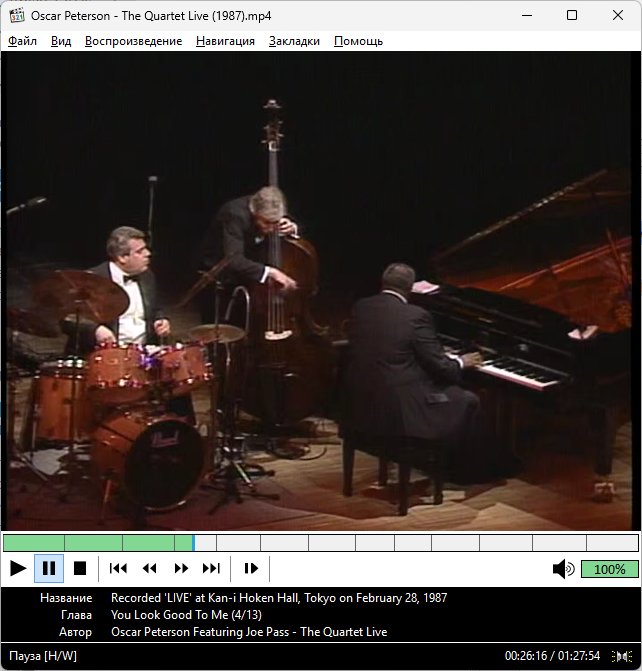
P. S. Вместо ручного заполнения названий частей и заголовков можно взять их из онлайн-каталога, где есть API. Вот вариант с Discogs.
Cсылка на этот конкретный DVD: https://www.discogs.com/ru/release/19022464-Oscar-Peterson-Featuring-Joe-Pass-The-Quartet-Live, оттуда надо взять идентификатор — это цифры после слова release.
# Получение данных
$release = Invoke-WebRequest https://api.discogs.com/releases/19022464 -UserAgent "FooBarApp/3.0" |ConvertFrom-Json
# Cписок треков для метаданных и заголовки задаются уже из полученной информации с сайта
$titles = $release.tracklist.title
";FFMETADATA1
title=$($release.title)
artist=$($release.artists_sort)
" > file.ffmeta